ЭКСПЕРИМЕНТЫ С ЗАДЕРЖКАМИ МИКРОКОНТРОЛЛЕРОВ.
Идея пришла в голову во время изучения темы программного UART-а для рабочего DWIN-проекта. Там везде куча туда-сюда HEX данных, ёбаный этот modbus и все такое. Как известно, точность передачи данных во многом зависит от синхронизации побитовых задержек между принимающим и передающим устройствами. Однако, чем меньше скважность нашего меандра, тем меньше точности в работе таких функций какy _us_delay(1). Отсюда идет ограничение по максимальному бод-рейту. На данный момент для Атмеги, тактирующейся от кварцевого резонатора 16 МГц верхний порог упирается где-то в 115200. О мегабите, кажется, можно даже не мечтать, потому что дальше уже приемник будет получать сплошное серево из каких-нибудь бессмысмленных вопросиков и квадратиков. И даже аппаратный таймер, настроенный на микросекунду, едва ли нам поможет, поскольку при порядке исчисления 1 * 10 ^ -6 секунды он неизбежно начнет пиздеть. А вот насколько - мы тут как раз и установим. Проверим, проясним и запротоколируем. Вместе с картинками, осцилограммами и так далее.
Вообще, я уже этим занимался, но ничего не записывал, поэтому толком нихера не помню, но думаю это все-таки необходимо сделать, так как иначе и крокодил не ловится и не растет кокос, я просто тупо не понимаю нихуя что делать в той или иной ситуации, приходится по-новой изобретать один и тот же велосипед. А начнем, пожалуй, с постановки задачи: сейчас мы попытаемся заставить микроконтроллер инвертировать состояние произвольного пина с интервалом в одну микросекунду. Причем, в рамках данной статьи, рассмотрим сразу несколько микроконтроллеров. Только постепенно. То есть, по мере продвижения научных изысканий, статья будет обновляться.
Итак, начнем с Атмеги без уточнения номера так как они все одинаковые. Как сказал классик, "... вот точно такой же миной только меньше, но другой...".
Atmega, версия 16 МГц кварц.
Рассмотрим сначала пример мигалки по аппаратному таймеру. Здесь у нас задана искомая скважность, чисто программно все Ок:
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); // Настройка таймера 1 TCCR1A = 0; // Установить регистры в 0 TCCR1B = 0; OCR1A = 1; // Установка регистра совпадения для микросекундного интервала TCCR1B |= (1 << WGM12); // Включить CTC режим TCCR1B |= (1 << CS11); // Установить предделитель 8 (CS11 = 1) TIMSK1 |= (1 << OCIE1A); // Включить прерывание по совпадению таймера sei(); // Разрешаем глобальные прерывания } // Основной цикл программы void loop() { while (1) { // Основной код программы } } // Прерывание по совпадению таймера 1 с OCR1A ISR(TIMER1_COMPA_vect) { // Инвертируем состояние пина TX_PIN PORTB ^= (1 << TX_PIN); } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается }
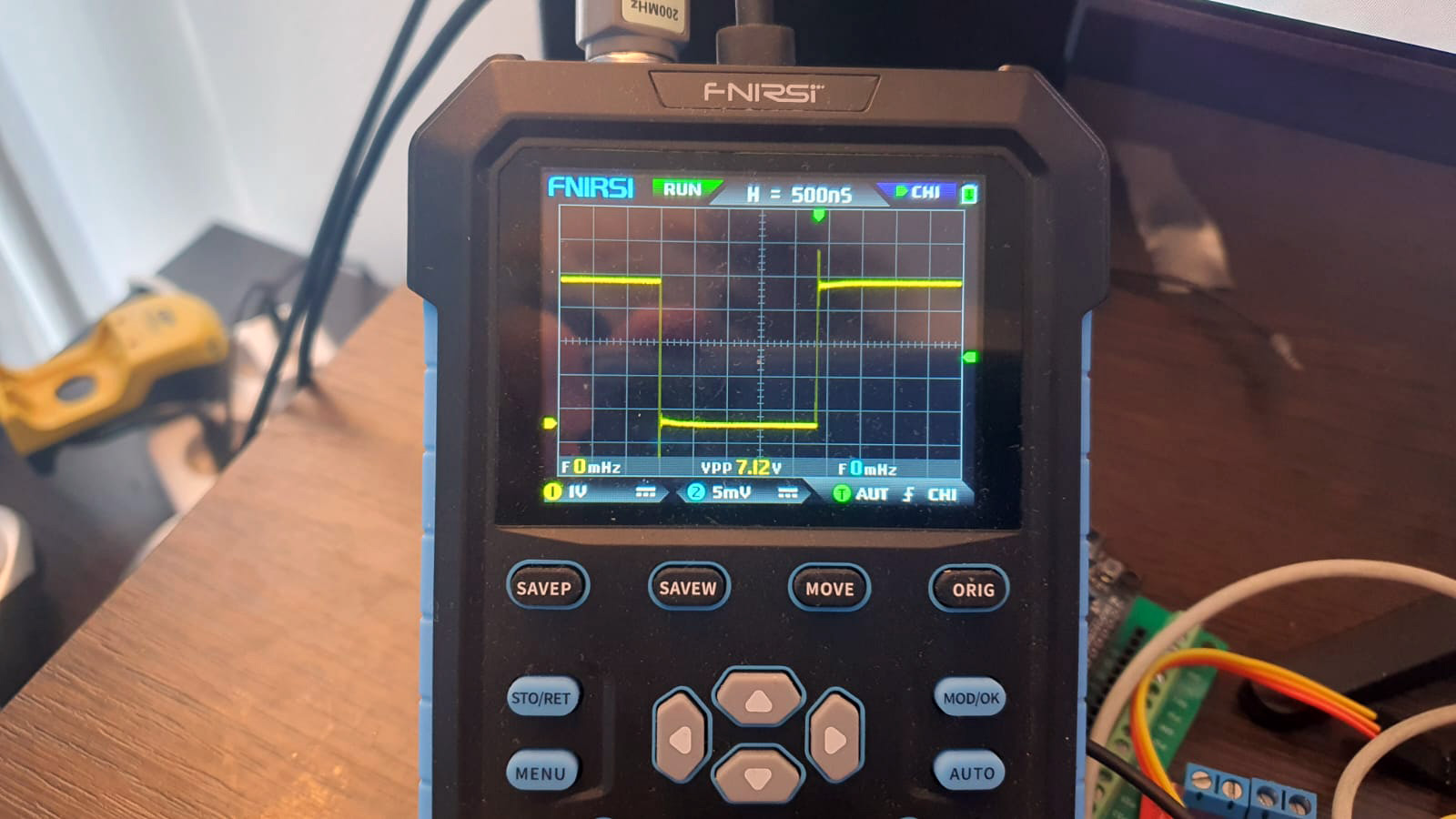
Однако на фото мы видим, что по факту у нас где-то около 2,3 микросекунды вместо одной. Теперь попробуем перенести инверсию состояния пина в loop:
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); // Настройка таймера 1 TCCR1A = 0; // Установить регистры в 0 TCCR1B = 0; OCR1A = 1; // Установка регистра совпадения для интервала 125 наносекунд TCCR1B |= (1 << WGM12); // Включить CTC режим TCCR1B |= (1 << CS10); // Установить предделитель 1 (CS10 = 1) TIMSK1 |= (1 << OCIE1A); // Включить прерывание по совпадению таймера sei(); // Разрешаем глобальные прерывания } // Основной цикл программы void loop() { while (1) { // Основной код программы PORTB ^= (1 << TX_PIN); } } // Прерывание по совпадению таймера 1 с OCR1A ISR(TIMER1_COMPA_vect) { // Инвертируем состояние пина TX_PIN } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается }
Единственный плюс - это то, что стало хотя бы не так криво:
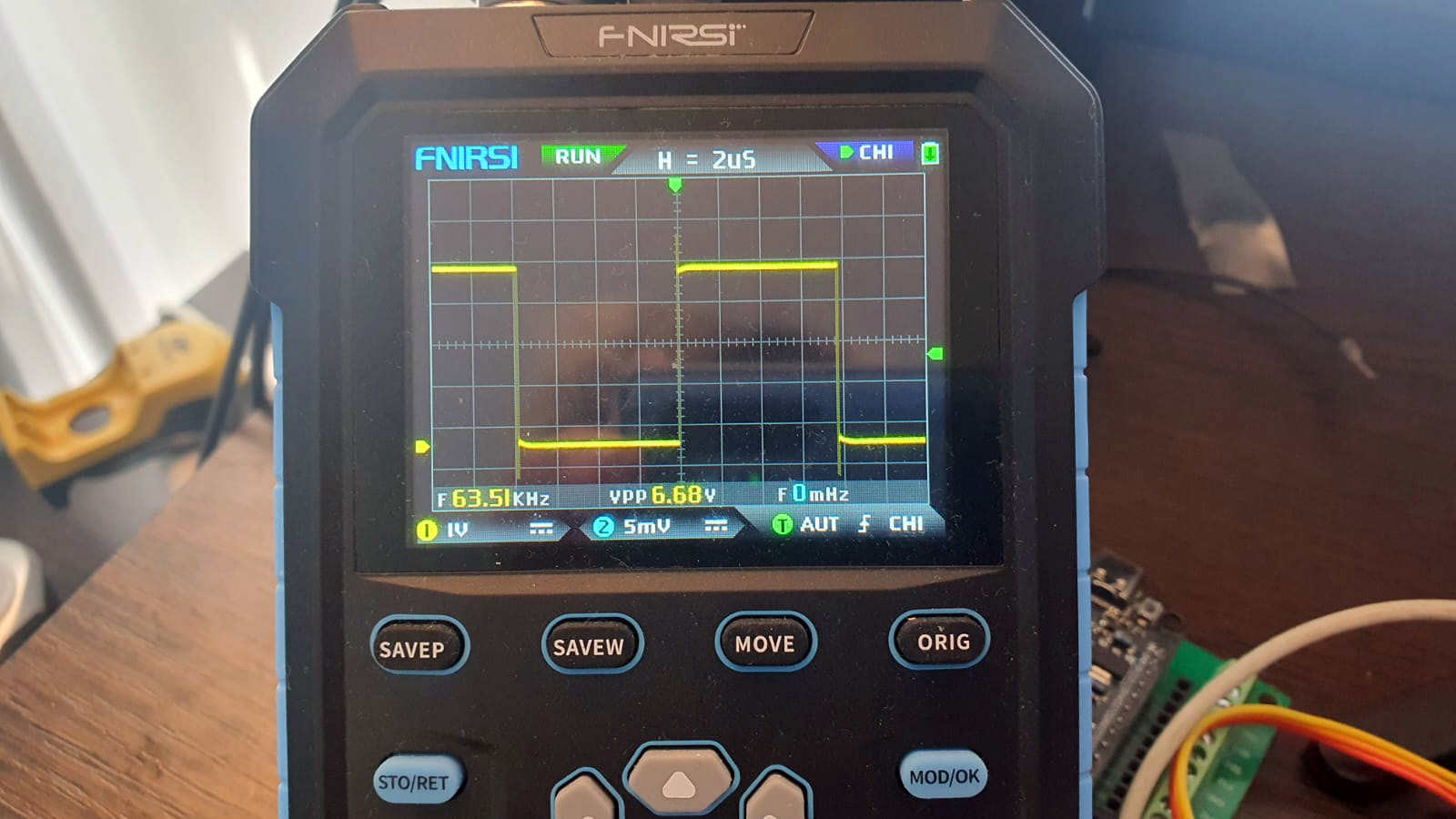
Однако мы только удалились от желаемого результата. На этот раз получился меандр со скважностью в 8 микросекунд. Обратим внимание на то, что настройки аппаратного таймера у нас сохранились, прерывания разрешены (sei). Команда инверсии пина PB0 просто переместилась из обработчика прерываний в другое место. Далее попробуем чистый loop(), без лишних затей:
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); } // Основной цикл программы void loop() { while (1) { // Основной код программы PORTB ^= (1 << TX_PIN); } } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается }
Это уже можно назвать каким-то промежуточным успехом:
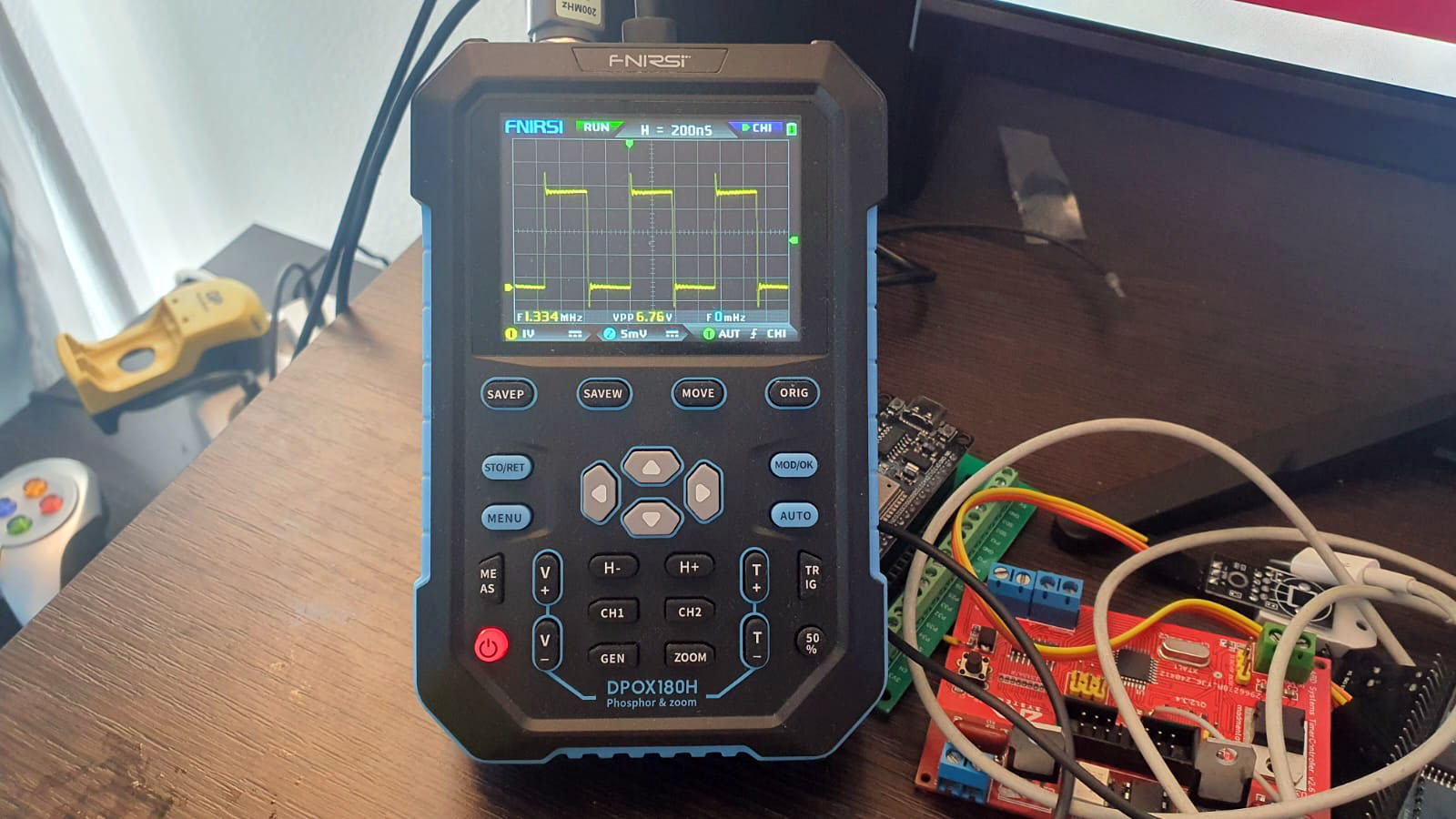
Хоть и кривенькие, но все-таки это уже 400 наносекунд, что на 600 меньше искомого значения... Теперь попробуем добавить несколько ассемблерных вставок для пропускания лишних тактов микроконтроллера.
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); } // Основной цикл программы void loop() { while (1) { // Основной код программы PORTB ^= (1 << TX_PIN); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); } } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается }
Ну и достаем из погреба шампанское! Это победа! Мы получили то, к чему так стремились!
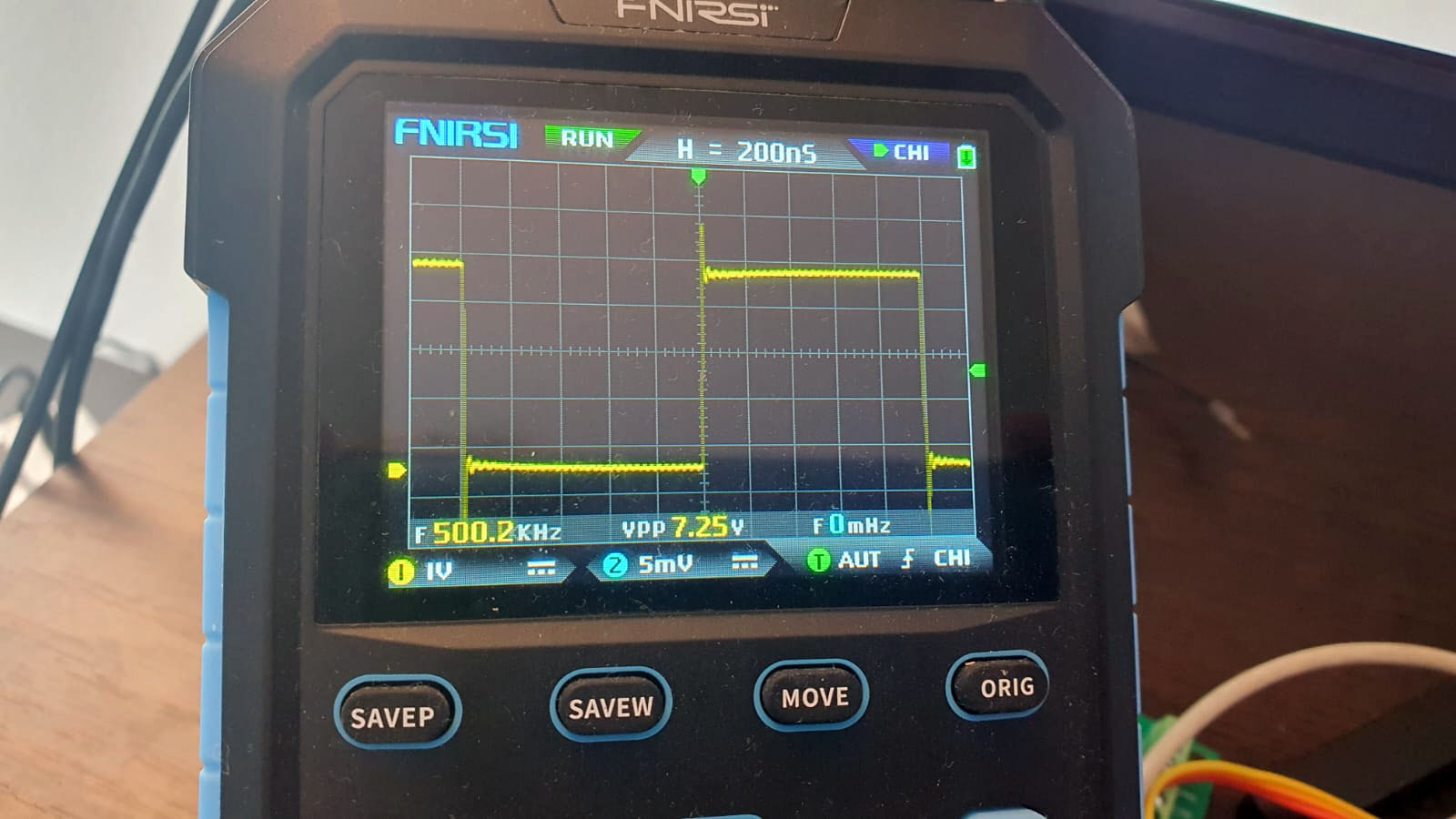
Однако, подводя итог, я бы отметил, что данный способ получения задержки в микросекунду может оказаться не всегда уместным и, к тому же, следует помнить о том, что для успешного его применения в других проектах мы должны отключать прерывания cli(), а затем разрешать их снова sei(). Здесь я специально верну настройки таймера, потому что в реальной жизни они практически всегда присутствуют и это не должно мешать нашей задержке.
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); // Настройка таймера 1 TCCR1A = 0; // Установить регистры в 0 TCCR1B = 0; OCR1A = 1; // Установка регистра совпадения для микросекундного интервала TCCR1B |= (1 << WGM12); // Включить CTC режим TCCR1B |= (1 << CS11); // Установить предделитель 8 (CS11 = 1) TIMSK1 |= (1 << OCIE1A); // Включить прерывание по совпадению таймера sei(); // Разрешаем глобальные прерывания } // Основной цикл программы void loop() { while (1) { // Основной код программы cli(); PORTB ^= (1 << TX_PIN); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); asm("nop"); sei(); } } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается } // Прерывание по совпадению таймера 1 с OCR1A ISR(TIMER1_COMPA_vect) { // Инвертируем состояние пина TX_PIN PORTB ^= (1 << TX_PIN); }
Как это будет выглядеть, сейчас посмотрим:
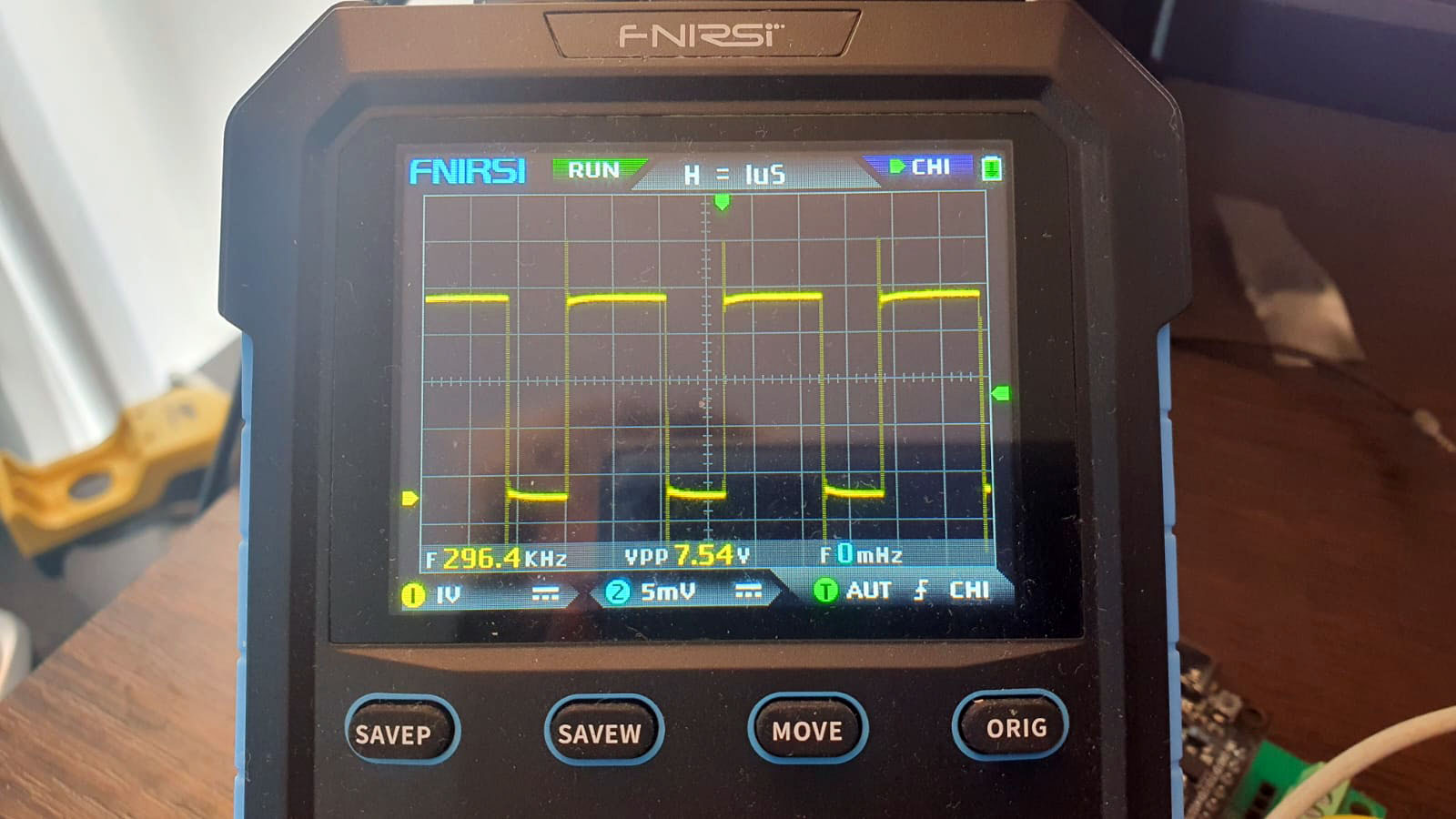
Очевидный косяк. Тут у нас высокий уровень длится чуть больше 2-х микросекунд, а низкий чуть больше одной. Если убрать ассемблерные вставки, то картина к лучему не меняется. Высокий уровень после этого длится 1,5 микросекунды, а низкий где-то 1,3. То есть, если циклически выключать и включать прерывания, наш метод создания задержки не заработает. И это надо учитывать... Если у нас имеется какой-то алгоритм, типа
// Функция для передачи одного байта данных через программный UART void software_uart_transmit(unsigned char data) { // Start bit TX_PORT &= ~(1 << TX_PIN); // Передаем LOW (стартовый бит) _delay_us(BIT_DELAY); // Длительность стартового бита // Data bits (8 бит данных) for (uint8_t i = 0; i < 8; i++) { if (data & (1 << i)) { TX_PORT |= (1 << TX_PIN); // Передаем HIGH } else { TX_PORT &= ~(1 << TX_PIN); // Передаем LOW } _delay_us(BIT_DELAY); // Длительность каждого бита } // Stop bit TX_PORT |= (1 << TX_PIN); // Передаем HIGH (стоповый бит) _delay_us(BIT_DELAY); // Длительность стопового бита }
Тогда нам надо расставлять cli/sei в начале и в конце:
// Функция для передачи одного байта данных через программный UART void software_uart_transmit(unsigned char data) { cli(); // Start bit TX_PORT &= ~(1 << TX_PIN); // Передаем LOW (стартовый бит) nopDelay(BIT_DELAY_MS); // Длительность стопового бита // Длительность стартового бита // Data bits (8 бит данных) for (uint8_t i = 0; i < 8; i++) { if (data & (1 << i)) { TX_PORT |= (1 << TX_PIN); // Передаем HIGH } else { TX_PORT &= ~(1 << TX_PIN); // Передаем LOW } nopDelay(BIT_DELAY_MS); // Длительность стопового бита } // Stop bit TX_PORT |= (1 << TX_PIN); // Передаем HIGH (стоповый бит) nopDelay(BIT_DELAY_MS); // Длительность стопового бита sei(); }
И да, я тут добавил функцию nopDelay(), принимающую int BIT_DELAY_MS. Мне так видится, чтобы не писать ручками все эти ассемблерные ставки, их можно сгенерировать из нашей переменной. Такая конструкция может понадобиться для генерации какого-нибудь ШИМ-сигнала, например. Или для настройки программного UART с помощью ручной крутилки энкодера.
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB void nopDelay(int count) { for (int i = 0; i < count; i++) { asm volatile("nop"); } } // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); } // Основной цикл программы void loop() { while (1) { // Основной код программы PORTB ^= (1 << TX_PIN); nopDelay(10); } } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается }
Здесь мы использовали 10 asm("nop") инструкций, как и было в том примере, где нам удалось добиться задержки ровно в одну микросекунду. Однако на этот раз получился косяк:
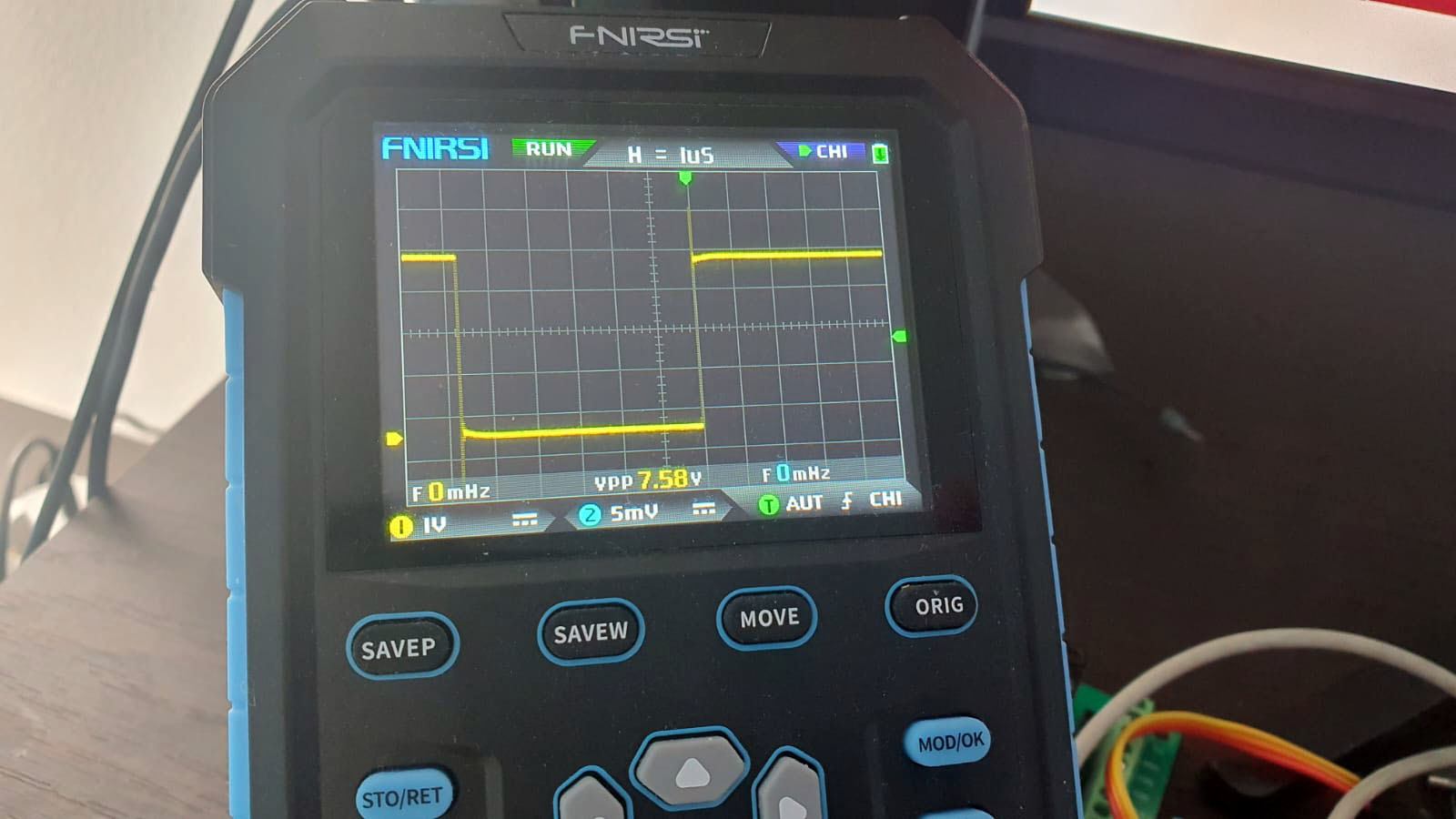
Попытки добиться необходимого результата, оставив цикл for внутри nopDelay ни к чему не привели. Cледующий код заработал корректно:
#define F_CPU 16000000UL // Тактовая частота 16 МГц #include <avr/io.h> #include <avr/interrupt.h> #define TX_PIN PB0 #define TX_DDR DDRB int count = 1; void nopDelay() { asm("nop"); asm("nop"); asm("nop"); } // Инициализация таймера void setup() { // Устанавливаем TX_PIN как выход TX_DDR |= (1 << TX_PIN); } // Основной цикл программы void loop() { while (1) { // Основной код программы PORTB ^= (1 << TX_PIN); nopDelay(); } } int main(void) { setup(); // Инициализация loop(); // Основной цикл return 0; // Никогда не достигается }
Однако задать количество итераций при помощи какой-то переменной не получается никак. Проблема еще в том, что если для задержки в одну микросекунда nopDelay содержит 3 пропуска такта, то это вовсе не означает что для десяти микросекунд потребуется тридцать. Пиздабол-чат объясняет это "издержками" на выполнение фунции. Чисто экспериментально, зависимость нелинейная и трудно объяснимая. Прикол в том, что инструкция "nop", по хорошему, должна пропускать один такт, а один такт при 16 МГц продолжается 62,5 наносекунды. Интуитивно кажется, что десять тактов должны занимать 625 наносекунд, а по факту, как видно из первого успешного примера, выходит 1 микросекунда. И если учесть эту поправку и прибавить еще 10 пропусков такта, то, кажется, должна получиться задержка в 2 микросекунды, но в жизни все не так. Поэтому идея с подбором задержки для программного UART при помощи крутилки энкодера, к сожалению, отметается как нереализумая. Во всяком случае, при 16 МГц уж точно (точно?).
Вообще, когда берусь за таки эксперименты, то получается очень много ужасно утомительной возни, которая в какой-то момент кажется бессмысленной, но все-таки во мне до сих пор есть какое-то внутреннее стремление понять, как эта хуйня работает. Возможно, если у тебя 4 микросекунды требуют меньше пропусков по 10 чем 3 микросекунды, то тут дело кроется в работе компилятора или в архитектуре самого микроконтроллера... Ну, он же восьмибитный. То есть, выполняет, по идее, 8 каких-то операций за один такт. Хер его знает, что он может сделать за такт, а что нет. Возможно, там в тех же 8 битах есть инструкции, заложенные компилятором, для обработки следующих тактов. Соответственно, могут быть такие кажущиеся нелинейными ошибки, но это прктически уже квантовая, блядь, физика (привет Фрауэнфельдеру и Хенли). Я пока не улавливаю корелляций, не вижу никакой системы в экспериментальных данных. Наверно, я просто тупорылый мудак. Но хорошо хоть не Ява-программист, которого такие проблемы не ебут в принципе.
Кстати, пока писал эту статью, то подтвердил одну из своих теорий, навеянных историей инженера, который изобрел синий диод. В подобных вещах необходимо терпение и упорство. Но все это не имеет смысла без записей. Протоколировать надо если не все, то максимум, потому что дьявол кроется в деталях. И если ты прямо сейчас, глядя в книгу видишь фигу, то при случае кто-нибудь, если не ты, воспользовавшись твоим трудом, сможет сделать правильные выводы. Я вот подумал , что надо померить скорость выполнения базовых приемов Си++, таких как циклы while и так далее, таких как if-else, swhitch-case конструкции и прочая подобная хрень, при определенных условиях тактирования. Вообще, кстати, цикл for() или цикл while() как раз-таки при 16 Мегагерцах выполняется примерно в одну микросекунду. Интересно... Но эти знания надо систематизировать.